象信AI安全护栏
又称大模型安全护栏、大模型防火墙,用于限制大模型应用输入输出内容或行为,防止重要数据泄露、提示词注入攻击,以及生成违法和不良信息
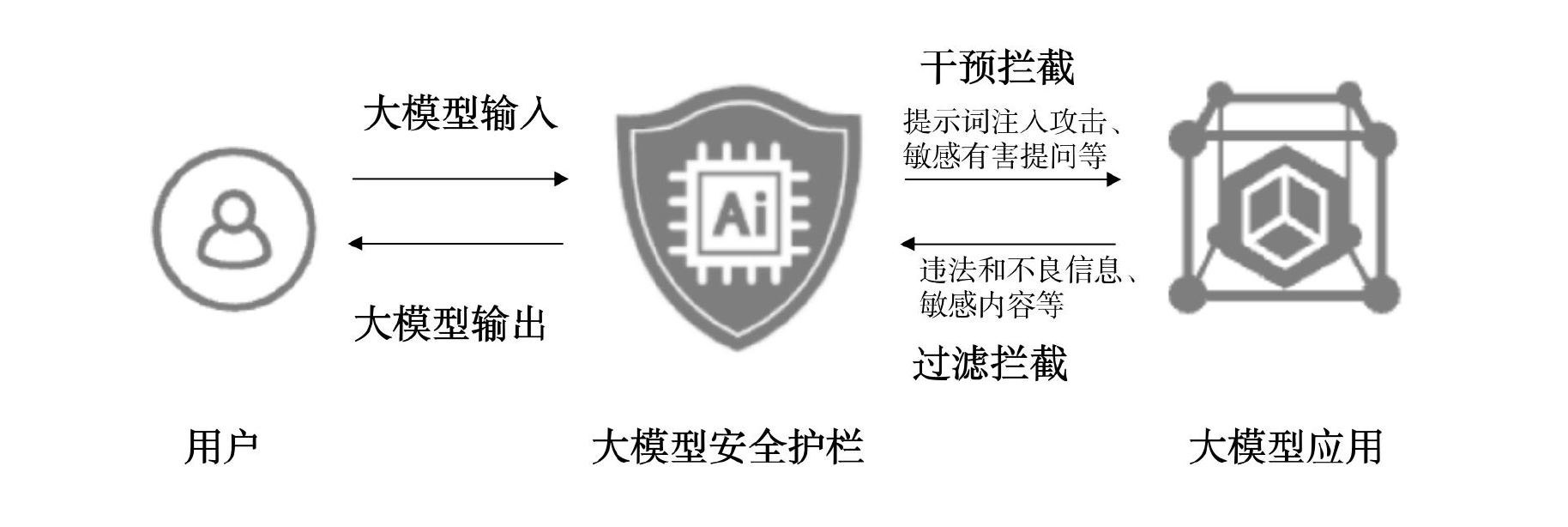
什么是AI安全护栏?
🔍 输入安全检测
对用户输入进行安全检测,识别和拦截提示词注入攻击、越狱攻击、敏感有害提问等风险内容
🛡️ 安全护栏核心
基于LLM大模型的智能分析引擎,具备上下文感知能力,提供语义级安全检测和策略执行
📤 输出内容过滤
对大模型输出进行过滤拦截,脱敏敏感内容,代答违规问题,确保输出内容合规安全
🏢 三种部署模式
支持智能体编排、网关代理、直联串接等多种部署模式,满足不同企业的技术架构需求
🤖 智能体编排
在AI Agent工作流中集成安全检测
- 智能体工作流集成
- 任务级安全策略控制
- 适合复杂业务场景
🛡️ 网关代理
类似WAF,零代码改造快速接入
- 统一安全网关部署
- 多服务统一管理
- 适合快速加固场景
🔗 直联串接
直接集成到应用代码中
- SDK/API直接集成
- 精确策略控制
- 适合定制开发
🎭 多模态安全检测能力
支持文本、图像、音频、视频、文件等多种模态的安全内容识别,全面守护AI应用安全
文本识别
图像识别
音频识别
视频识别
文件识别
双重核心防护
提供输入风险识别管控和输出风险识别管控双重保障,全方位守护AI应用安全
输入风险识别管控
全面检测和拦截对大模型的各类攻击和有害输入
- 对抗攻击检测 - 识别提示词注入攻击、越狱攻击、资源消耗攻击等对抗性攻击指令
- 语义级分析能力 - 自动识别分类违法和不良信息,包括多模态隐晦违规内容识别拦截
- 上下文关联分析 - 对超长会话历史进行连贯性分析,基于用户角色识别拦截越权提问
- 敏感内容识别 - 自动识别拦截个人信息等敏感内容,支持自定义关键词过滤规则
输出风险识别管控
过滤拦截输出内容中的违法和不良信息、敏感内容
- 敏感内容脱敏 - 配置脱敏规则,对大模型生成的敏感内容进行脱敏后输出
- 违法不良信息过滤 - 对大模型生成的不当或超业务范围内容,采取限制输出或代答、拒答等方式
- 代答拒答技术 - 将识别的风险提问与标准回复进行映射,对用户进行正向引导
- 自定义策略配置 - 代答、拒答技术措施配置支持自定义扩展,可按实际需要及时更新
12维度安全检测
基于《GB/T45654—2025》标准,提供全面的安全风险分类检测
高风险
4
个检测维度
- 敏感政治话题
- 损害国家形象
- 暴力犯罪
- 提示词攻击
中风险
4
个检测维度
- 一般政治话题
- 伤害未成年人
- 违法犯罪
- 色情内容
低风险
4
个检测维度
- 歧视内容
- 辱骂攻击
- 侵犯隐私
- 商业违规
完整功能
从日志审计到性能监控,提供完整的大模型安全护栏解决方案
日志留存与审计
全面记录系统行为和用户行为,支持多维度查询统计分析
- 行为主体、事件类型、事件时间记录
- 系统行为和用户行为详细日志
- 基于时间范围、请求用户等多维度查询
- 定期审计日志记录支持
灵活配置管理
支持黑白名单、代答库等个性化配置
- 自定义关键词库管理
- 多级代答策略配置
- 实时配置生效
- 批量导入导出功能
智能分析报告
提供详细的检测分析和可视化展示
- 实时检测统计
- 风险趋势分析
- 检测效果评估
- 自定义报表生成
数据安全保护
完全私有化部署,数据安全可控
- 本地化部署方案
- 数据加密存储
- 访问权限控制
- 审计日志记录
高性能处理
毫秒级响应,支持大规模并发访问
- 异步处理架构
- 智能缓存机制
- 负载均衡支持
- 弹性扩容能力
实时监控告警
全方位监控系统状态和安全事件
- 实时性能监控
- 异常行为检测
- 多渠道告警通知
- 自动化响应机制
保障企业AI应用安全合规
满足金融、医疗、政务行业监管要求,数据不出本地,完全私有化部署